
商品画像をAIに学習させる
最近流行している、 「画像認識」に挑戦してみましょう。
AIに商品画像を学習させます。
まずは下のYouTube動画をご視聴いたいただくと、より理解が進みます。
画像認識とは?
Python と聞くと、AI(人工知能)、機械学習、 ディープラーニングなどのキーワードを連想する人も少なくないと思います。
今回紹介するのは、機械学習による画像認識です。機械学習とは、大量のデータを与えるだけで自動的に学習が進み、AIが予測や分類できるようになる技術です。
今回はバッグや財布などの商品画像を学習させて、写っている商品を自動的に見分けるプログラムを目指します。

これまで商品を見分けるためには、バーコードやQRコード、RFタグなどが使われてきました。 つまり、プログラムが認識しやすい情報を付けてあげていたわけです。
画像認識の精度が上がれば、人間と同じように見ただけで商品を見分け、 会計なども行えるようになります。
このプログラムは商品の区別だけでなく、文字や顔の認識などいろいろな場面に応用できますよ。
 てらやん
てらやん学習させる画像を変えれば、他のことにも応用できるってことですね。
サンプルファイルとプログラム
画像ファイルをもとにAIに学習させて学習モデルを生成する
機械学習は一般的に「大量の学習用データを渡してモデルに学習させる」「学習後のモデルを利用して予測・分類を行う」の2ステップで行います。まず学習させたい商品と商品コードをまとめたExcelファイルを作成します。 1行目に「商品コード」 「商品名」 という列名を入力します。
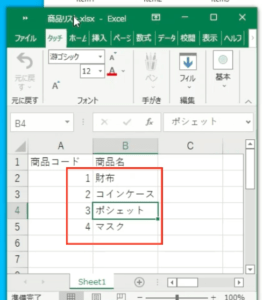 てらやん
てらやんAIの一番大事なところですね。 人間の頭脳みたいなイメージがありますね。ところで 「モデル」 って何なのですか?
モデルとは、簡単には説明できないのですが、 学習用のアルゴリズムと学習によって得た特徴量が1つになったものです。学習後にファイルとして保存しておけば、他のプログラムで利用できるんですよ。
次に、商品コードのフォルダに商品の画像を準備しましょう。 Excelファイルと対応させる必要があるので、フォルダ名は「item (商品コード)」の形にします。
例えば、 商品コード1の財布の画像は 「item1」 フォルダに入れます。
商品の写り方が違っていても対応できるよう、なるべくさまざまな角度や距離から撮影した画像を用意しましょう。
学習させる画像が多いほど認識精度が上がります。 サンプルではそれほど多くは用意していないのですが、 実用で使うなら可能な限り多くの画像を用意したほうがいいでしょう。
Excelファイルと画像フォルダは、プログラムファイル (ai_learn.py) と同じ階層に置いてください。
準備ができたら、ai_learn.pyを実行しましょう。
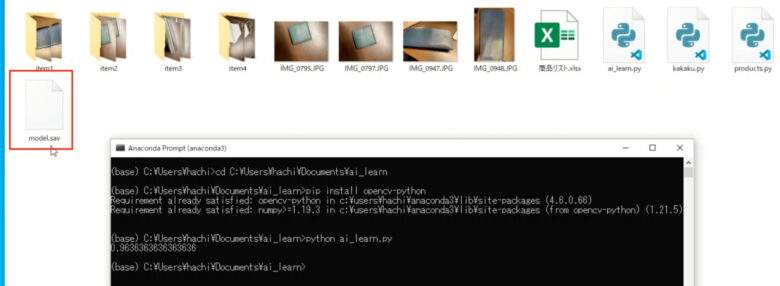
数値 (0.96363・・・) が表示され、 「model.sav」というファイルが出力されます。 これがモデルを保存したファイルです。
学習結果の妥当性を0から1の数値で表したもので、1に近いほど妥当であることを示します。
それではプログラムを見ていきましょう。
サンプルでは学習用のデータ数が少ないので、そこまで信用で
きる値とはいえません。 目安程度に考えてください。
import os
import cv2
import glob
import pandas as pd
import numpy as np
from sklearn import svm
import pickle
current_dir = os.getcwd()
labels = []
images = []
df = pd.read_excel("商品リスト.xlsx")
for index, row in df.iterrows():
image_path = os.path.join(current_dir, "item"+str(row["商品コード"]))
os.chdir(image_path)
# フォルダ内の画像ファイルを取り出す
for file in glob.glob("*.JPG"):
# 画像を学習しやすいように加工する
img = cv2.imread(file)
img = cv2.resize(img, (64, 64))
img = img.flatten()
# ラベルと画像をリストに追加する
labels.append(row["商品名"])
images.append(img)
os.chdir(current_dir)
# 学習モデルを作成する
model = svm.SVC(decision_function_shape='ovr')
# モデルを学習させる
model.fit(images, labels)
# 相関を表示
print(model.score(images, labels))
# 学習データをファイルに保存
pickle.dump(model, open("model.sav", "wb"))大部分はExcelファイルと画像ファイルを読み込み、それらをリストに格納する前準備です。
まずread_excel関数でExcelファイルを読み込み、1行ずつ 「商品コード」と「商品名」を繰り返し処理していきます。
画像処理にはcv2というパッケージを使用し、 imread 関数で画像ファイ商品コードが1なら、 「item1」 フォルダ内の全JPEGファイルを読み込みます。
cv2パッケージはインストールする必要があります。コマンドライン上で
pip install opencv-python
としてインストールします。

resize 関数で64×64pxにリサイズし、 flatten メソッドでコントラストの自動調整を行っています。 これらの処理を行うのは、画像のサイズや明暗がバラバラだと学習しにくいからです。 処理後の画像は変数images に、商品名を変数 labels に追加します。
一連の処理が終わると、 商品画像 images と商品名 labelsの2つのリストができあがっています。 これらを使って画像を学習させます。
学習には scikit-learn (サイキット・ラーン) パッケージのSVMモジュールを利用します。
SVMモジュールは「サポートベクターマシーン」 を利用するためのもので、専門的にいうと教師あり学習を行う機械学習モデルの一種なのですが、説明し始めるとキリがありません。今回は使い方だけを学んでください。
svm.SVC (・・・・・・) で学習前のモデルを作成し、fit メソッドで2つのリストをもとに学習させます。 これで「財布の写真の特徴」 と 「財布というラベル」を紐付けて学習されます。 最後に学習モデルのスコアを表示したあと、pickleモジュールを使って学習後のモデルを 「model.sav」 というファイルとして保存します。
pickle は、 Python のオブジェクトをそのままファイルとして保存する機能を提供します。
要はモデルを作ったら、 データを渡して学習 (fit) させて、pickle で保存ですね!
このプログラムを他のことに応用したいときは、Excelファイルの商品名を変更すればいいでしょう。
前のプログラムで学習した結果を使って商品を認識し、商品名を答えさせましょう。
ステップ2では、学習した結果を使って画像を認識させてみましょう。
まず、逆のプログラムで作成した学習後のモデルのファイル (model.sav)をプログラム (products.py)と同じフォルダに置いてください。次に、認識させたい商品の画像を準備し、プログラムと同じフォルダに置きましょう。
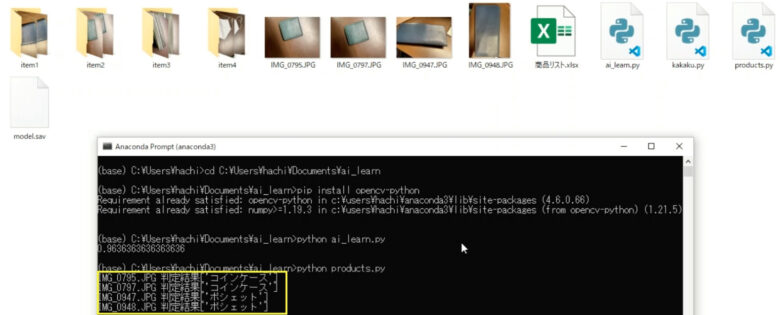
products.py
import cv2
import glob
from sklearn import svm
import pickle
#学習モデルの読み込み
model = pickle.load(open("model.sav", 'rb'))
#フォルダ内の画像ファイルを取り出す
for file in glob.glob("*.JPG"):
img = cv2.imread(file)
#画像を学習しやすいように加工する
img = cv2.resize(img, (64, 64))
img = img.flatten()
print(file,"判定結果"+str(model.predict([img])))pickleモジュールとpredictメソッドで画像を認識させる
まずpickleモジュールで、 前のプログラムで作成した学習モデルを読み込んでいます。
そして、フォルダ内のJPEGファイルを繰り返し処理で画像認識させています。 画像の読み込みには学習時と同様にcv2パッケージを使用します。
imread 関数で画像を読み込み、 resize 関数で64×64pxにリサイズし、 flattenメソッドでコントラストを自動調整しています。
認識させる画像は学習したときと同じ処理 (今回のresize、flatten) を行っておかないと、認識がうまくいきません。
最後に predictメソッドに画像を渡して、 判定結果を画面に表示しています。
てらやん認識するときは、学習モデルを読み込んでpredict メソッドに画像を渡すだけでいいんですね!
けっこう簡単!
商品の価格を取り出すプログラム
まとめの応用例として、 画像認識の結果を利用して、商品の価格を取り出してみましょう。
前節のプログラムで、 画像を読み込むだけでその商品名を判別できるようになりました。 さらに応用して、 画像認識した商品の価格を答えるプログラムを作ってみましょう。
まず、 商品の価格をExcelファイルにまとめましょう。 前のプログラムで使使用した「商品リスト.xlsx」の表のC列に価格を入力していきます。 1行目に 「価格」 と入力し、 2行目以降に対応する商品の価格を入力してください。
プログラム (kakaku.py) を実行すると、 認識結果と商品の価格が表示されます。
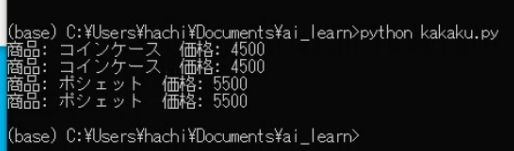
import cv2
import glob
from sklearn import svm
import pickle
import pandas as pd
#学習モデルの読み込み
model = pickle.load(open("model.sav", 'rb'))
#フォルダ内の画像ファイルを取り出す
for file in glob.glob("*.JPG"):
img = cv2.imread(file)
#画像を学習しやすいように加工する
img = cv2.resize(img, (64, 64))
img = img.flatten()
#画像認識の結果を取得
result_item = model.predict([img])[0]
#商品リストの読み込み
df = pd.read_excel("商品リスト.xlsx",index_col="商品名")
#価格を取得
price = df.at[result_item,"価格"]
print("商品:",result_item," 価格:",price)プログラムを見てみましょう。 学習モデルを読み込み、 フォルダ内のJPEGファイルを繰り返し処理で画像認識させるところまでは、products.py とほとんど同じです。
追加した部分は、Excelファイルを読み込んで、価格表から認識した商品の価格を抜き出す部分です。
pandas の read_excel関数でExcelファイルを読み込む際に、 index_colという引数を指定して、 商品名をインデックスにしたDataFrameオブジェクトにします。
こうしておくと、at[result_item, “価格”] とするだけで、 画像認識結果の商品名の価格を取り出すことができます。
最後に商品名と価格を表示して完了です。
てらやん認識結果をExcel ファイルと照らし合わせて、価格を抜き出しているんですね。
フォルダ内に複数の画像ファイルがあれば、それらもまとめて読み込んで結果を表示してくれますよ。
てらやん結果として出た価格を使って計算とかすれば、さらに自動化できそうですね!