
 はち
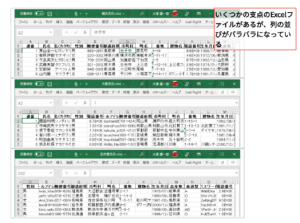
はち以前に複数のCSVファイルを連結する⽅法を説明しましたが、それぞれのファイルを作る⼈が異なっていために、表の形式が違ってしまったなんてこともよく聞く話ですね。
項目がバラバラなExcelファイルを一つにまとめる
例えば列名が異なっていたり、列の順番が変わっていたりする場合、機械的に連結したらめちゃくちゃなデータになってしまいます。
今回は、項目が異なっている表を連結するプログラムを紹介します。
実行手順
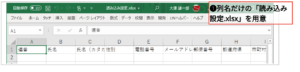
まず、仕上がりの列の並びを指定する仕上がり設定.xlsxを⽤意します。
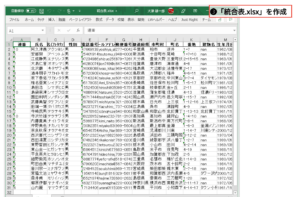
プログラムを実⾏すると、フォルダ内のExcelファイルを連結した統合表.xlxを作成します。
サンプルとコード
サンプルファイルから下のボタンからダウンロードしてください
inconsistent.py
import pandas as pd
import glob
cols=pd.read_excel("仕上がり設定.xlsx")
result_list=[]
for input_file in glob.glob("*支店.xlsx"):
df=pd.read_excel(input_file,dtype='object',engine="openpyxl")
for index,row in df.iterrows():
work=[]
for col in cols:
if col in df.columns:
work.append(str(row[col]))
else:
work.append("")
result_list.append(work)
df=pd.DataFrame(result_list,columns=cols.columns)
df_result=df.sort_values(["氏名(カタカナ)"])
with pd.ExcelWriter("統合表.xlsx") as writer:
df_result.to_excel(writer,index=False)コードの解説
「仕上がり設定.xlsx」を読み込み、DataFrameオブジェクトを変数colsに⼊れます。
glob関数を使い、「*.⽀店.xlsx」というパターンに合うファイルの⼀覧を取得します。ただの「*.xlsx」というパターンだと「仕上がり設定.xlsx」なども読み込んでしまうため、ファイル名の末尾が「⽀店」であることもパターンに⼊れています。
そのあとは三重ループです。ただし、列の順番をそろえるために、⼀番内側のループの処理が変わっています。この部分についてはあとでまとめて説明しましょう。
最後に連結したファイルをDataFrameオブジェクトにし、それをto_excelメソッド保存しています。今回のデータは名簿なので、並べ替えを⾏うsort_valuesメソッドを使って昇順に並べ替えています。
「仕上がり設定.xlsx」のデータを列ごとにに分割し、それに対して繰り返し処理をしています。そのため、列の順番は「仕上がり設定.xlsx」にそろうことになります。
ただし、⽀店のデータの中に「仕上がり設定.xlsx」の列に相当するデータがない場合もありえます。具体的には、「横浜⽀店.xlsx」にはパスワード列がありません。そのため、該当する列があるかどうかをif⽂とin演算⼦でチェックし、ある場合は2重リストに追加し、ない場合は空⽂字列(””)を追加しています。
2重リストにデータを追加していることにも要注⽬です。colには「仕上がり設定.xlsx」から取り出した列名、rowには各⽀店のExcelファイルから取り出した1⾏分のデータ(Seriresオブジェクト)が⼊っています。そこで「row[col]」と書くと、⽀店データの中から特定の列名のデータを取り出すことができるのです。あとは2重リストにappendメソッドで追加するだけです。