
pandasをインストール
padasiは、表データを読み込んで、データの追加や抽出、集計、書き出しなどを行える外部ライブラリです。
windowsにインストールするときはコマンドプロンプト
pip install pandas
macOSにインストールするときは、ターミナル
pip3 install pandas
表データは、テーブルと呼ばれます。横方向に並んでいる行と、縦方向に並んでいる列でできています。
行は、レコードやロウとも呼ばれます。
列は、カラムや項目とも呼ばれます。
CSVファイルとは何か
表データをファイルに保存するときに、CSVファイルがよく使われます。CSVファイルとは、カンマで区切られたデータが何行も入ったテキストファイルです。ファイルの一行が1件のデータで、カンマで区切られた1つ1つが要素です。1番左に数字が並んでいます。これをインデックスといいます。
test.csvとstep3/step3.py(フォルダとファイル名は自由です。step1、2はスクレイピングの記事でhttps://blogsmile117.com/scraping/にあります)を同じフォルダに入れます。
pandasでcsvファイルを開く
df=pd.read_csv(“test.csv”)
print(df)
でcsvファイルを読み込むことができます。それをdfという変数に代入しています。
変数名dfで実行しています。
CSVデータを解析する
読み込んだデータの情報を調べてみます。データの件数は、「len(df)」、項目名は「df.columns.values」、インデックスは「df.index.values」調べることができます。
step3-2.py
df=pd.read_csv(“test.csv”)
print(“データの件数=” , len(df))
print(“項目名=” , df.columns.values)
print(“インデックス=” , df.index.values)

列データ、行データを表示する
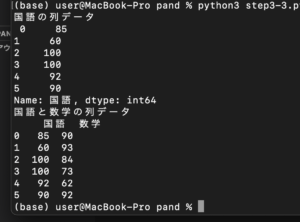
df[“列名”]と指定すると、その1列のデータを取得できます。複数列のデータは、df[“列名2” , “列名2”]と、リストで指定して取得します。test.csvの国語と数学の列データを表示させます。
step3-3.py
df=pd.read_csv(“test.csv”)
#1列のデータ
print(“国語の列データ\n” , df[“国語”])
#複数の列のデータを表示
print(“国語と数学の列データ\n” , df[[“国語” , “数学”]] )
行データの取得
1行のデータは、df.loc[行番号]と指定するとその1行のデータを取得できます。複数行のデータは、df.loc[[行番号1,行番号2]]と、リストで指定して取得できます。また、1つの要素は、df.loc[行番号][“列名”]と、行と列を指定することで所得できます。
test.csvのインデックス「2」行と「3」行のデータと、インデックス「2」行の「国語」の要素を表示してみましょう。
df=pd.read_csv(“test.csv”)
print(“Cのデータ\n”,df.loc[2])
print(“CとDのデータ\n”,df.loc[[2,3]])
print(“Cの国語のデータ\n” ,df.loc[2][“国語”])
列データを、行データを削除する
指定した列を削除するには、df.drop(“列名”,axis=1)、指定した行を削除するには、df.drop(行番号,axis=0)と指定します。
3-6.py
df=pd.read_csv(“test.py”)
print(“名前の列を削除\n”,df.drop(“名前”,axis=1))
print(“インデックス2を削除\n”,df.drop(2,axis=0))
必要な情報を抽出する
df =df.read_csv(“test.csv”)
data_s=df[df[“国語”]>=90]
print(“国語が90点以上\n” , data_s)
data_c=df[df[“数書”]<70]
print(“数学が70点未満\n”,data_c)
データを集計する
表データを集計することができます。最大値はdf[“列名”].max()、最小値はdf[“列名”].min()、平均値はdf[“列名”].mean()、中央値はdf[“列名”].median()、合計値はdf[“列名”].sum()で求めることができます。数学の集計を表示してみます。
3-8.py
df=pd.read_csv(“test.csv”)
print(“数学の最高点=”,df[“数学”].max())
print(“数学の最低点=”,df[“数学”].min())
print(“数学の平均点=”,df[“数学”].mean())
print(“数学の中央値=”,df[“数学”].median())
print(“数学の合計=”,df[“数学”].sum())
データを並び替える
項目を指定して並び替えをすることができます。df.sort_values(“列名”)と命令します。
昇順(1、2、3……)
df=df.sort_values(“列名”)
降順
df=df.sort_values(“列名”,ascending=False)
chap3-9.py
df=pd.read_csv(“test.py”)
kokugo=df.soret_values(“国語”,ascending=Falese)
print(“国語の点数がタイアkもの順でソート\n”,kokugo)
行と列を入れ替える
表データの行と列を入れ替えることができます。例えば、DataFrameに「.T」をつけるだけで入れ替わります。またDataFrameを、Pythonで使うリストに変換することもできます。「.values」とつけるだけです。
import pandas as pd
df=pd.read_csv(“test.csv”)
print(“行と列を入れ替える\”,df.T)
print(“データをリスト化する\n”,df.values)
CSVファイルに出力する
DataFrame.to_csv(ファイル名.csv”)とします。インデックスやヘッダーを削除して出力したいときには、=Falseとします。
国語の点数で並び替えて、CSVファイルに出力してみます。
3-11.py
df=pd.read_csv(“test.csv”)
kookugo=df.sort_values(“国語” , ascending=False)
kokugo.to_csv(“export1.csv”)
グラフで表示してみる
matplotlibをインストール
データフレームの情報を取得する.info()
データフレームの統計量を取得
.describe()
roundメソッド
桁数を指定して数値を丸める
population.describe().round(0)
データフレームの作り方
リストの方を持った配列を使う
import pandas as pd
df=ps.DataFrame( [[1,2,3,],[4,5,6,),[7,8,9]],
columns=[‘col01’,’col02’,’col03’],
index=[‘idx01’,’idx02’,’idx03’])
実行
df
結果

numpyの配列をつかう
numpyとは高速にリストの計算をするためのライブラリです。
import numpy as np
df=pd.DataFrame(np.array( [ [123],[4,5,6],[7,8,9] ] ),
columns=[‘col01’,’col02’,’col03’],
index=[‘idx01’,’idx02’,idx03’] )
df
df.indexで行を取得
df.columnsで列を取得
辞書型でフレームワーク
df=pd.DataFrame({ ‘col01’:[1,2,3],
‘col02’:[4,5,6],
‘col03’:[7,8,9]}
,index=[‘index’,’index02’,’index03’])
df
df.columns=[‘col01′,’col02′,’c0l03′]
df.index=[‘idx01′,’idx02′,’idx03′]
カラムを上書き
df.columns=[‘col04’,’col05′,’c0l06’]
renameメソッド
行名・列名を変更する
df=df.rename(columns={‘col04:’x’})
df
列をシリーズとして取得
df[‘x’]
列をデータフレーム形式で取得
df[[‘x’]]
locメソッド
行名や列名を指定して、行や列を取得
df.loc[‘W’]
列全部を取得
df.loc[:,’col01’]
カンマの前が行、後ろが列を表している。